JSON on the Apple II
About two and a half years ago, I wrote a JSON parser in 6502 assembly language. It’s been hanging around in relative obscurity until now. A couple of days ago, JSON65 saw a huge traffic spike, due to being posted on Hacker News. I thought I would take this opportunity to provide some background and answer a few questions that were raised.
Background
I grew up in the 1980s, when personal computers were quite different than they are today. (Indeed, the concept of a “personal” computer was rather new back then.) Most computers that were sold for home use had an 8-bit microprocessor, one or two 5¼" floppy disk drives, and something on the order of 64 KiB of RAM.
My first encounter with a computer was when my dad brought home an NCR DM-V from work so that he could write his Master’s thesis using WordStar. The computer could also run Microsoft BASIC, and my dad showed me how to write programs in BASIC. Once I discovered a magical book called the “manual”, which revealed all the secrets of BASIC, I was on a roll. I wrote a lot of programs in BASIC for that computer.
Alas, the DM-V was just on loan, and my dad had to return it to work when he finished his thesis. To replace it, my parents bought an Apple //e. I continued writing programs in BASIC on the Apple //e. I was really into it. I had the Beagle Bros Peeks and Pokes chart. I subscribed to Open-Apple/A2-Central. I was so into it that my dad had to make a “no computer before 6 AM” rule, because otherwise I would get up arbitrarily early to program.
Applesoft BASIC was incredibly slow, and also didn’t provide access to all of the features of the hardware. So, I started to learn 6502 assembly language. Initially, I just wrote small parts of my programs in assembly language, since it was easy to mix BASIC and assembly language on the Apple II. I assembled my programs with the mini-assmebler which was available in the Integer BASIC ROM image (which was loaded into the Language Card RAM area under DOS 3.3).
Eventually, I needed something more powerful than the mini-assembler. The obvious solution might have been to buy an assembler, but assemblers were expensive for a kid back then, plus I just enjoyed making things myself. So, around 8th grade or so, I wrote my own assembler in BASIC, which I called PPAssemble. It worked, but PPAssemble was so slow that I really only used it for one thing: to bootstrap PPAssemble II, which was an assembler I wrote in assembly language.
All of this came to an end when I graduated from high school. My parents gave me a 486 laptop which ran MS-DOS and Windows 3.1. (Perhaps unsurprisingly, one of the things I did over the summer was write an 8086 assembler in QBasic.) Then, in the fall, MIT introduced me to UNIX, and shortly after that I learned C.
Retrocomputing
Fast forward to 2018, when I got the old Apple //e out of the garage and started using it again. I installed the cc65 cross-compilation toolchain on my Mac, and started writing code for the Apple II again.
Why JSON?
The three main reasons I wrote a JSON parser in 6502 assembly language were:
- Because I can.
- Because it’s fun!
- Because it’s a bit perverse.
However, the specific motivation for writing a JSON parser was because I was writing some other program (which I don’t think I ever finished) and I wanted a configuration file format for it, an ASCII format which could be easily hand-written. YAML was a logical choice, but YAML is fairly complicated, so I went with the much simpler JSON.
My first thought was to compile YAJL with cc65. I eventually got it to compile, but there were a couple of problems:
- YAJL is huuuuuuge! (by 6502 standards, anyway)
- It didn’t work.
Rather than trying to debug why YAJL didn’t work correctly when compiled with cc65, I decided to just write a JSON parser from scratch.
Why assembly language?
The main reason I got the Apple //e out again was to relive my glory days of programming in 6502 assembly language. So, that was the primary motivation for writing my JSON parser in assembly language. However, there are also some practical motivations for doing so:
- The 6502 instruction set is not a particularly good match for C.
- cc65 is a relatively naive compiler, compared to a modern optimizing compiler like gcc or clang.
- Both code size and speed are important on the Apple II, since it is very slow (1 MHz, with each instruction taking several clock cycles) and has limited memory (48K, 64K, or 128K, depending on how you count it, and how much work you’re willing to go to to access it).
Then why is it written in four languages?
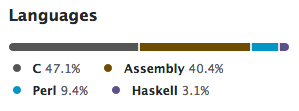
JSON65 is written in two languages, C and 6502 assembly language.
The JSON parser is a single file, json65.s. So, it is correct to say that the JSON parser is written entirely in 6502 assembly language. However, it is designed to be called from C, because it uses the cc65 calling convention. It also calls a few of the support functions in cc65’s runtime library: callptr4, incsp4, incsp6, negeax, pushax, resteax, and saveeax. (These functions are for manipulating the “pseudo-registers” in the zero page that the cc65 calling convention uses.)
JSON65 includes some additional, optional code beyond the core event-driven parser, most of which is written in C. json65-file.c feeds the parser from a file, and json65-tree.c provides a tree-based interface to the parser, as an alternative to the SAX-style event-driven parser.
GitHub’s code analysis also shows Perl and Haskell code in the JSON65 repository. This is because of the tools directory, which contains some scripts which I used to generate some code when I was writing JSON65. The average user of JSON65 doesn’t need these. And in any case, they run on the host, not on the 6502!
Why are strings limited to 255 characters?
Because JSON65 can parse incrementally, a JSON document like this:
[ "This is a string" ]could be fed into the parser in two chunks. For example, the first chunk could be:
[ "This isand the second chunk could be:
a string" ]In order to provide the string "This is a string" to the callback, one of the following things must happen:
The callback must be called twice (with
"This is"and" a string"), and the user of the library must deal with putting the two parts together. I didn’t want to do this, because it makes the library harder to use.The parser must copy the two parts of the string into a dynamically allocated buffer, which it can then provide to the callback. I didn’t want to do this, because the Apple II has very little memory, and I didn’t want to leave to chance whether or not you would run out of memory during parsing.
The parser must copy the two parts of the string into a statically allocated buffer, which it can then provide to the callback. This is the solution I chose, but it means that strings are limited to the length of the buffer.
So, there had to be a limit on the length of strings. Why 255 bytes, specifically? This is because of addressing modes.
The 6502 offers an indirect indexed addressing mode, for example:
LDA ($40),Ywhich loads a 16-bit integer from the consecutive zero-page locations $40 and $41. It then adds the contents of the Y register (which is 8 bits wide) to that 16-bit integer. That result is used as an address, and a single byte is loaded from that address and placed in the accumulator.
This makes it easy to index into a buffer of 256 bytes or fewer. Just store the address of the buffer somewhere in the zero page, and then load the Y register with the array index.
To index into a buffer longer than 256 bytes, you’d need to do 16-bit addition (8 bits at a time) to add the base address to the index, and then store the result in the zero page somewhere. Then you’d load 0 into the Y register, and you’d still use the same indirect indexed addressing:
LDA ($40),Y(because the original 6502 does not offer an indirect, non-indexed addressing mode.)
Doing so would not be the end of the world, but it is more instructions, so therefore it takes more space and more time. Given that the buffer has to be of some finite size, 256 bytes seems like a fine choice.
(I believe I limited the length to 255, rather than 256, so that the length of the string can also fit in a single byte.)
Note that although the length of a string is limited, the length of a line is not limited. So, for example, you could have a JSON document like this:
[ "Up to 255 chars", "Up to 255 chars", "Up to 255 chars" ]all on a single line, where each of the three strings on the line is up to 255 characters in length. (Technically 255 bytes, not characters, but that distinction only matters if you’re using non-ASCII characters.)